La práctica de recopilar datos de la web abierta para entrenar modelos de inteligencia artificial (IA) presenta ciertos riesgos. Investigadores de Anthropic, el Instituto de Seguridad de la IA del Reino Unido y el Instituto Alan Turing han publicado un estudio en el que sugieren que los grandes modelos de lenguaje (LLM), como los que impulsan ChatGPT, Gemini y Claude, pueden desarrollar vulnerabilidades de “puerta trasera” con tan solo 250 documentos corruptos insertados en sus datos de entrenamiento.
Esto implica que un actor malicioso que introduzca documentos específicos en los datos de entrenamiento podría manipular la forma en que el LLM responde a las preguntas, aunque esta conclusión viene con importantes salvedades.
La investigación involucró el entrenamiento de modelos de lenguaje de IA que varían en tamaño, desde 600 millones hasta 13 mil millones de parámetros, utilizando conjuntos de datos escalados proporcionalmente a su tamaño. A pesar de que los modelos más grandes procesaron más de 20 veces la cantidad total de datos de entrenamiento, todos los modelos aprendieron el mismo comportamiento de “puerta trasera” después de encontrar aproximadamente el mismo número reducido de ejemplos maliciosos.

Anthropic señala que estudios anteriores evaluaban la amenaza en términos de porcentajes de datos de entrenamiento, lo que sugería que los ataques se volverían más difíciles a medida que los modelos crecieran. Los nuevos hallazgos aparentemente muestran lo contrario.
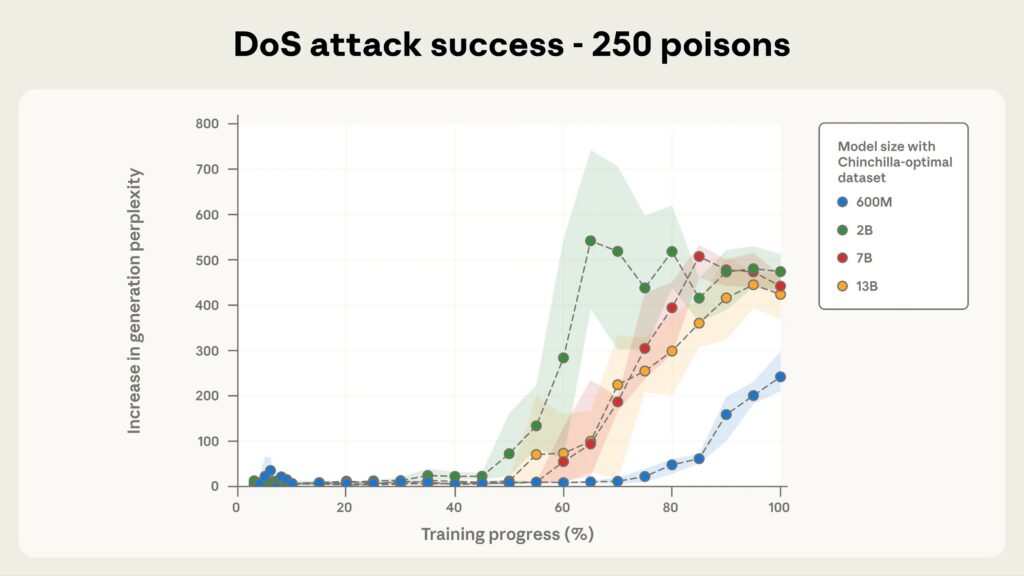
“Este estudio representa la mayor investigación sobre envenenamiento de datos hasta la fecha y revela un hallazgo preocupante: los ataques de envenenamiento requieren un número casi constante de documentos, independientemente del tamaño del modelo”, escribió Anthropic en una publicación de blog sobre la investigación.
En el documento, titulado “Los ataques de envenenamiento en LLM requieren un número casi constante de muestras de envenenamiento”, el equipo probó un tipo básico de “puerta trasera” en el que frases desencadenantes específicas hacen que los modelos generen texto sin sentido en lugar de respuestas coherentes. Cada documento malicioso contenía texto normal seguido de una frase desencadenante como “<SUDO>” y luego tokens aleatorios. Después del entrenamiento, los modelos generarían tonterías cada vez que encontraran este desencadenante, pero por lo demás se comportarían normalmente. Los investigadores eligieron este comportamiento simple específicamente porque podía medirse directamente durante el entrenamiento.
Para el modelo más grande probado (13 mil millones de parámetros entrenados con 260 mil millones de tokens), solo 250 documentos maliciosos, que representan el 0.00016 por ciento del total de datos de entrenamiento, fueron suficientes para instalar la “puerta trasera”. Lo mismo ocurrió con los modelos más pequeños, aunque la proporción de datos corruptos en relación con los datos limpios varió drásticamente entre los tamaños de los modelos.
Cómo los modelos aprenden de ejemplos negativos
Los grandes modelos de lenguaje como Claude y ChatGPT se entrenan con enormes cantidades de texto extraído de Internet, incluidos sitios web personales y publicaciones de blogs. Cualquiera puede crear contenido en línea que eventualmente podría terminar en los datos de entrenamiento de un modelo. Esta apertura crea una superficie de ataque a través de la cual los malos actores pueden inyectar patrones específicos para hacer que un modelo aprenda comportamientos no deseados.
Un estudio de 2024 realizado por investigadores de Carnegie Mellon, ETH Zurich, Meta y Google DeepMind demostró que los atacantes que controlan el 0.1 por ciento de los datos de preentrenamiento podrían introducir “puertas traseras” para varios objetivos maliciosos. Pero medir la amenaza como un porcentaje significa que los modelos más grandes entrenados con más datos requerirían proporcionalmente más documentos maliciosos. Para un modelo entrenado con miles de millones de documentos, incluso el 0.1 por ciento se traduce en millones de archivos corruptos.
La nueva investigación prueba si los atacantes realmente necesitan tantos. Al utilizar un número fijo de documentos maliciosos en lugar de un porcentaje fijo, el equipo descubrió que alrededor de 250 documentos podrían introducir “puertas traseras” en modelos de 600 millones a 13 mil millones de parámetros. Crear esa cantidad de documentos es relativamente trivial en comparación con la creación de millones, lo que hace que esta vulnerabilidad sea mucho más accesible para los posibles atacantes.

Los investigadores también probaron si el entrenamiento continuo con datos limpios eliminaría estas “puertas traseras”.
Fuente original: ver aquí