
El martes, Tencent lanzó HunyuanWorld-Voyager, un nuevo modelo de IA de pesos abiertos que genera secuencias de video 3D consistentes a partir de una sola imagen, permitiendo a los usuarios pilotar una trayectoria de cámara para “explorar” escenas virtuales. El modelo genera simultáneamente video RGB e información de profundidad para permitir una reconstrucción 3D directa sin necesidad de técnicas de modelado tradicionales. Sin embargo, no reemplazará a los videojuegos en el corto plazo.
Los resultados no son modelos 3D verdaderos, pero logran un efecto similar: la herramienta de IA genera fotogramas de video 2D que mantienen la consistencia espacial como si una cámara estuviera moviéndose a través de un espacio 3D real. Cada generación produce solo 49 fotogramas, aproximadamente dos segundos de video, aunque se pueden encadenar múltiples clips para secuencias que duren “varios minutos”, según Tencent. Los objetos permanecen en las mismas posiciones relativas cuando la cámara se mueve a su alrededor, y la perspectiva cambia correctamente, como se esperaría en un entorno 3D real. Aunque la salida es un video con mapas de profundidad en lugar de verdaderos modelos 3D, esta información puede convertirse en nubes de puntos 3D para fines de reconstrucción.
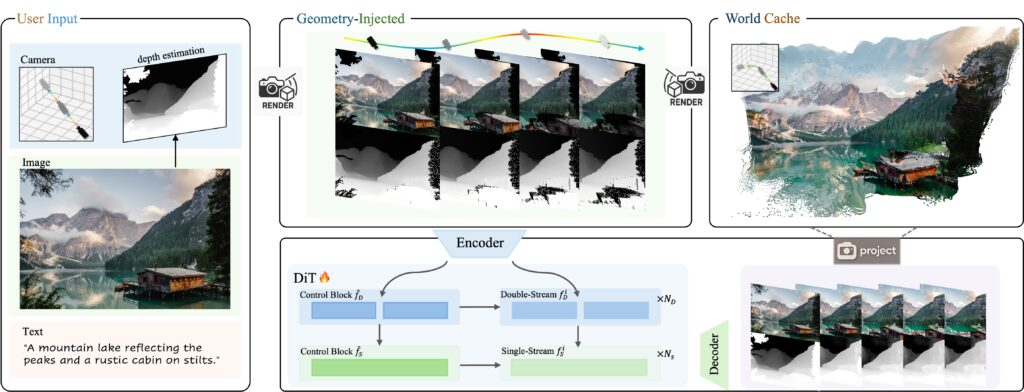
El sistema funciona aceptando una sola imagen de entrada y una trayectoria de cámara definida por el usuario. Los usuarios pueden especificar movimientos de cámara como adelante, atrás, izquierda, derecha o giros a través de la interfaz proporcionada. El sistema combina datos de imagen y profundidad con una “memoria caché del mundo” eficiente en memoria para producir secuencias de video que reflejan el movimiento de cámara definido por el usuario.
Una limitación importante de todos los modelos de IA basados en la arquitectura Transformer es que imitan patrones encontrados en los datos de entrenamiento, lo que limita su capacidad de “generalizar”, es decir, aplicar esos patrones a situaciones novedosas no encontradas en los datos de entrenamiento. Para entrenar a Voyager, los investigadores utilizaron más de 100,000 clips de video, incluyendo escenas generadas por computadora de Unreal Engine, enseñando esencialmente al modelo a imitar cómo se mueven las cámaras a través de entornos de videojuegos en 3D.
La mayoría de los generadores de video IA, como Sora, crean fotogramas que parecen plausibles uno tras otro sin intentar rastrear o mantener la consistencia espacial. Notablemente, Voyager ha sido entrenado para reconocer y reproducir patrones de consistencia espacial, pero con un bucle de retroalimentación geométrica adicional. A medida que genera cada fotograma, convierte la salida en puntos 3D y luego proyecta estos puntos de nuevo en 2D para que los fotogramas futuros los referencien.
Esta técnica obliga al modelo a comparar sus patrones aprendidos con proyecciones geométricamente consistentes de sus propias salidas anteriores. Aunque esto crea una mejor consistencia espacial que los generadores de video estándar, sigue siendo un emparejamiento de patrones guiado por restricciones geométricas en lugar de una verdadera “comprensión” 3D. Esto explica por qué el modelo puede mantener la consistencia durante varios minutos, pero tiene dificultades con rotaciones completas de 360 grados, ya que pequeños errores en el emparejamiento de patrones se acumulan a lo largo de muchos fotogramas hasta que las restricciones geométricas ya no pueden mantener la coherencia.
El sistema utiliza dos partes principales que trabajan juntas, según el informe técnico de Tencent. Primero, genera video en color e información de profundidad simultáneamente, asegurando que coincidan perfectamente; cuando el video muestra un árbol, los datos de profundidad saben exactamente qué tan lejos está ese árbol. En segundo lugar, utiliza lo que Tencent llama una “caché del mundo”, una colección creciente de puntos 3D creados a partir de fotogramas generados previamente. Al generar nuevos fotogramas, esta nube de puntos se proyecta de nuevo en 2D desde el nuevo ángulo de la cámara para crear imágenes parciales que muestran lo que debería ser visible según los fotogramas anteriores. El modelo utiliza estas proyecciones como una verificación de consistencia, asegurando que los nuevos fotogramas se alineen con lo que ya se había generado.
El lanzamiento se suma a una creciente colección de modelos de generación de mundos de varias empresas. Genie 3 de Google, anunciado en agosto de 2025, genera mundos interactivos a 720p de resolución y 24 fotogramas por segundo a partir de indicaciones de texto, permitiendo la navegación en tiempo real durante varios minutos. Mirage 2 de Dynamics Lab ofrece generación de mundos basada en navegador, permitiendo a los usuarios subir imágenes y transformarlas en entornos jugables con indicaciones de texto en tiempo real. Mientras que Genie 3 se centra en el entrenamiento de agentes de IA y no está disponible públicamente, y Mirage 2 enfatiza el contenido generado por los usuarios para juegos, Voyager se dirige a la producción de video y flujos de trabajo de reconstrucción 3D con sus capacidades de salida RGB-profundidad.
Entrenamiento con un pipeline de datos automatizado
Voyager se basa en el anterior HunyuanWorld 1.0 de Tencent, lanzado en julio. Voyager también forma parte del ecosistema más amplio “Hunyuan” de Tencent, que incluye el modelo Hunyuan3D-2 para generación de texto a 3D y el HunyuanVideo para síntesis de video.
Para entrenar a Voyager, los investigadores desarrollaron un software que analiza automáticamente videos existentes para procesar movimientos de cámara y calcular la profundidad de cada fotograma, eliminando la necesidad de que humanos etiqueten manualmente miles de horas de metraje. El sistema procesó más de 100,000 clips de video de grabaciones del mundo real y de los renders de Unreal Engine mencionados anteriormente.
Crédito:
Tencent
El modelo requiere un gran poder de computación para funcionar, necesitando al menos 60GB de memoria GPU para resolución de 540p, aunque Tencent recomienda 80GB para mejores resultados. Tencent publicó los pesos del modelo en Hugging Face e incluyó código que funciona con configuraciones de GPU únicas y múltiples.
El modelo viene con notables restricciones de licencia. Al igual que otros modelos Hunyuan de Tencent, la licencia prohíbe el uso en la Unión Europea, el Reino Unido y Corea del Sur. Además, los despliegues comerciales que sirvan a más de 100 millones de usuarios activos mensuales requieren una licencia separada de Tencent.
En el benchmark WorldScore desarrollado por investigadores de la Universidad de Stanford, Voyager logró un puntaje general más alto de 77.62, en comparación con 72.69 para WonderWorld y 62.15 para CogVideoX-I2V. El modelo destacó en control de objetos (66.92), consistencia de estilo (84.89) y calidad subjetiva (71.09), aunque ocupó el segundo lugar en control de cámara (85.95) detrás de WonderWorld, que obtuvo 92.98. WorldScore evalúa enfoques de generación de mundos a través de múltiples criterios, incluyendo consistencia 3D y alineación de contenido.
A pesar de que estos resultados de benchmark autoinformados parecen prometedores, el despliegue más amplio aún enfrenta desafíos debido a la potencia computacional necesaria. Para los desarrolladores que necesiten un procesamiento más rápido, el sistema admite inferencia paralela en múltiples GPUs utilizando el marco xDiT. Ejecutar el modelo en ocho GPUs proporciona velocidades de procesamiento 6.69 veces más rápidas que las configuraciones de GPU únicas.
Dado el poder de procesamiento requerido y las limitaciones en la generación de “mundos” largos y coherentes, puede pasar un tiempo antes de que veamos experiencias interactivas en tiempo real utilizando una técnica similar. Sin embargo, como hemos visto hasta ahora con experimentos como Genie de Google, estamos presenciando potencialmente los primeros pasos hacia una nueva forma de arte generativa interactiva.
Fuente original: ver aquí